文章摘要的内容: 本文以“百家乐胜率赛前数据模型解析及其对最终结果的预测影响”为核心,对相关数据模型的理论基础、构建逻辑、分析方法以及预测价值进行系统梳理与深入探讨。文章首先从整体角度概括赛前数据模型在百家乐分析中的作用,强调其并非决定输赢的工具,而是一种用于理解概率结构与历史规律的分析框架。随后,正文从数据来源与概率基础、模型构建与参数选择、模型对结果预测的影响,以及模型应用的局限与理性认知四个方面展开详细阐述,逐层剖析数据模型如何在不确定性极高的博弈环境中提供参考信息。文章最后在总结部分再次强调理性看待数据模型的重要性,指出任何预测都无法改变随机本质,数据模型的真正价值在于帮助研究者建立更清晰的概率认知与风险意识,而非追求绝对准确的结果判断。
在探讨百家乐胜率赛前数据模型之前,首先需要明确其数据基础来源。通常,这类模型所依赖的数据包括历史牌局记录、庄闲胜负比例、和局出现频率以及发牌规则所决定的概率结构。这些数据为模型分析提供了客观素材,使研究者能够在大量样本中观察到长期稳定的统计特征。
从概率论角度看,百家乐是一种规则相对固定、概率透明的博弈形式。庄、闲、和三种结果在数学期望上存在明确差异,这为赛前胜率模型的建立奠定了理论前提。通过对规则的拆解,可以计算出在无限样本条件下各结果的理论概率,从而作为模型的基准参考。
然而,赛前数据模型并不只停留在理论概率层面,还会引入实际牌局数据进行对比分析。通过比较理论概率与历史统计概率之间的偏差,模型试图判断样本波动是否处于正常范围之内,从而为后续预测提供背景判断。
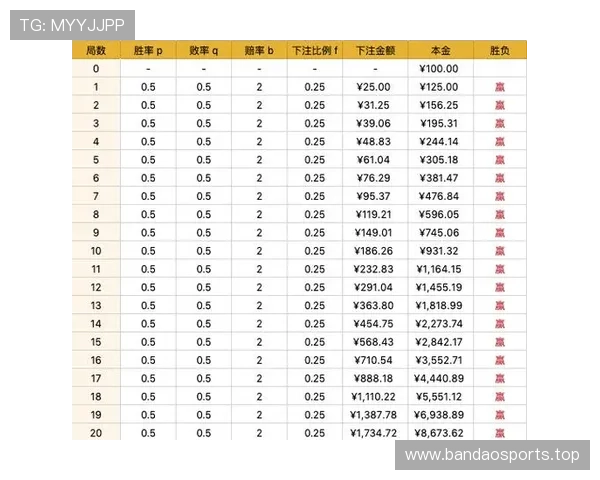
百家乐胜率赛前数据模型的核心在于模型构建过程。常见的方法包括频率统计模型、滑动窗口分析以及基于马尔可夫假设的状态转移模型。这些方法通过不同数学工具,对历史数据进行抽象与简化,以提半岛体育取可供分析的结构信息。
在模型构建过程中,参数选择尤为关键。例如,样本区间长度、权重分配方式以及是否区分不同牌靴阶段,都会直接影响模型输出结果。参数设置过于敏感,容易放大短期波动;参数过于平滑,又可能掩盖真实变化,这种平衡是模型设计中的重要课题。
此外,赛前数据模型往往需要不断校验与修正。通过回测历史数据,检验模型预测结果与实际结果之间的偏差,可以帮助研究者识别模型假设中的不足,从而逐步提高分析框架的稳定性与解释力。
从表面上看,百家乐胜率赛前数据模型似乎能够对最终结果产生一定预测指向,但这种影响更多体现在概率认知层面,而非确定性结论。模型输出的胜率变化,往往反映的是统计趋势,而不是对单一结果的精准判断。
在实际应用中,模型可能会提示某一阶段庄或闲的历史表现偏离长期均值,但这并不意味着未来结果必然向某一方向发展。随机性依然主导每一局牌的独立性,模型的预测影响更多是心理和策略层面的参考。
因此,正确理解预测影响尤为重要。将模型结果视为一种风险评估工具,而非结果保证,有助于避免对数据模型产生过度依赖,也能帮助研究者在分析过程中保持客观与理性。
尽管百家乐胜率赛前数据模型在分析层面具有一定价值,但其局限性同样明显。首先,模型无法改变游戏本身的随机属性,每一局牌在规则上都是相互独立的,这决定了任何预测都只能是概率层面的推测。
其次,数据模型容易受到样本偏差的影响。历史数据的数量、质量以及统计方式,都会对模型结论产生干扰。如果忽视这些前提条件,模型输出结果可能会被误读,甚至产生错误的判断方向。
因此,建立理性认知是使用赛前数据模型的关键。将模型作为研究工具,而非决策依赖,才能真正发挥其在理解概率、控制风险以及提升认知深度方面的积极作用。
总结:
综合来看,百家乐胜率赛前数据模型解析为理解游戏概率结构和历史规律提供了一种系统化视角。通过对数据基础、模型构建以及预测影响的分析,可以更清楚地认识到模型在理论研究和统计分析中的价值所在。
同时,文章也强调了理性看待预测结果的重要性。任何数据模型都无法突破随机性的边界,其真正意义在于帮助人们建立科学的概率思维与风险意识,从而在分析和研究过程中保持清醒与客观。






以便获取最新的优惠活动以及最新资讯!



